반응형
survey of large language models (2023) 논문에서 등장한 키워드들을 추출하였습니다.
- 대규모 언어 모델(LLM, Large Language Model) - 수십억 개 이상의 매개변수를 갖춘 신경망 기반 자연어 처리 모델로, 방대한 텍스트 데이터를 학습하여 높은 성능을 발휘하는 AI 모델.

- 자연어 처리(NLP, Natural Language Processing) - 인간의 언어를 컴퓨터가 이해하고 생성할 수 있도록 하는 기술 분야로, 기계 번역, 음성 인식, 텍스트 요약, 챗봇 등에 활용됨.

- 트랜스포머(Transformer) - 2017년 Google이 제안한 신경망 구조로, 자가 주의(Self-Attention) 메커니즘을 사용하여 병렬 연산이 가능하며, LLM의 핵심 기술로 사용됨.
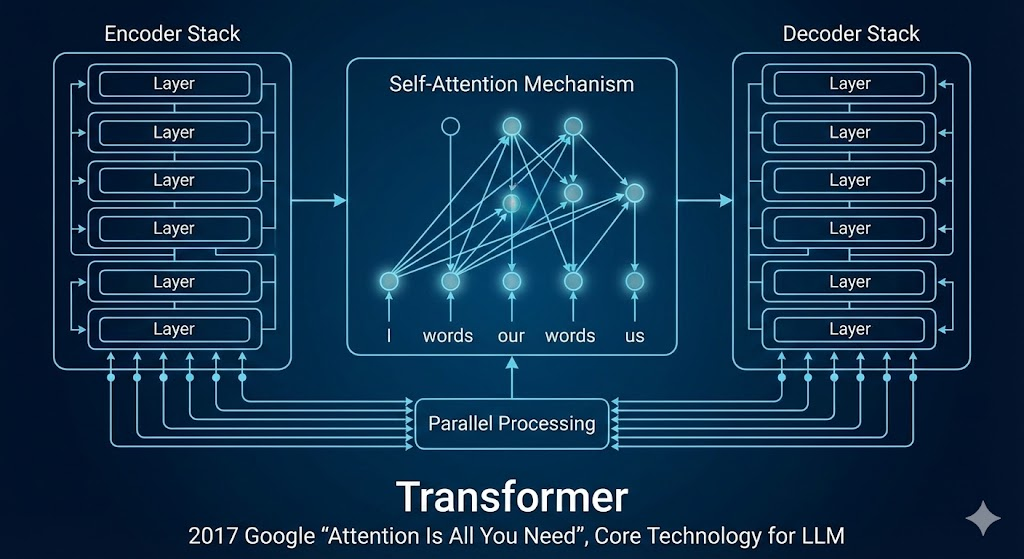
- 자가 주의(Self-Attention) - 문장의 각 단어가 다른 단어들과의 관계를 고려하여 가중치를 부여하는 방식으로, 문맥을 더 깊이 이해할 수 있도록 하는 핵심 메커니즘.

- 사전 학습 언어 모델(PLM, Pre-trained Language Model) - 대량의 텍스트 데이터를 활용하여 미리 학습된 언어 모델로, 특정 작업을 수행하기 위해 추가 학습(Fine-Tuning)이 필요함.

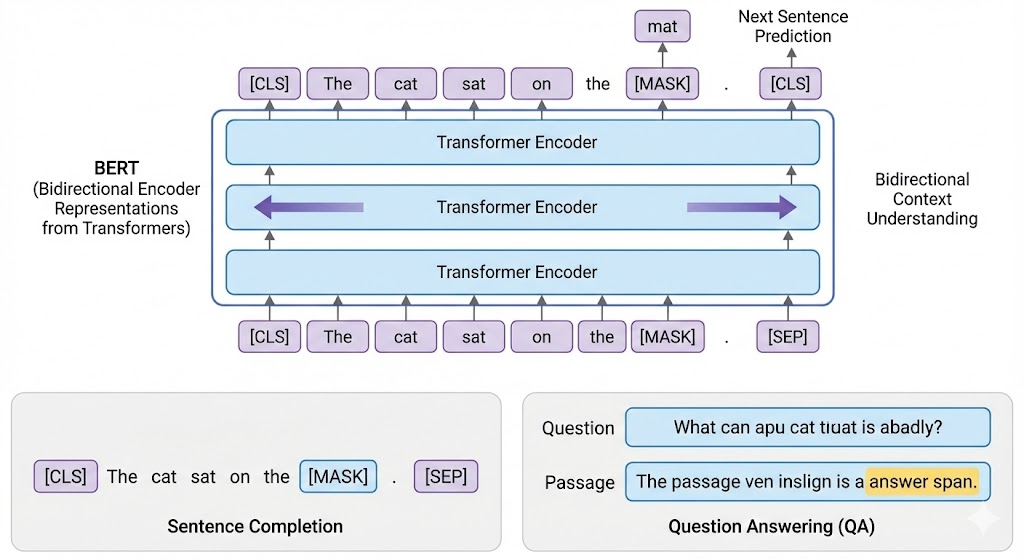
- BERT (Bidirectional Encoder Representations from Transformers) - 문맥을 양방향으로 이해할 수 있도록 설계된 트랜스포머 기반 모델로, 문장 완성, 질의응답 등 다양한 NLP 작업에 사용됨.
- 상황 내 학습(In-context Learning, ICL) - LLM이 별도의 추가 학습 없이 주어진 문맥(프롬프트)만으로 새로운 작업을 수행할 수 있는 능력.

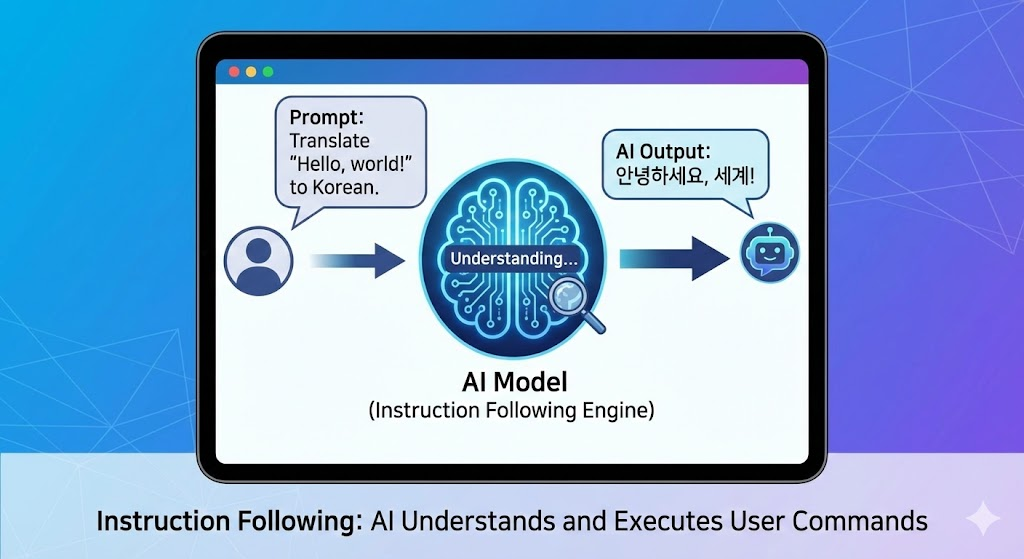
- 명령어 따르기(Instruction Following) - 사용자의 명령어(프롬프트)를 이해하고 적절한 출력을 생성하는 능력으로, AI 챗봇과 같은 응용 분야에서 중요함.
- 프롬프트(Prompt) - LLM에게 특정 작업을 수행하도록 지시하는 입력 문장 또는 텍스트.

- 파인튜닝(Fine-Tuning) - 사전 학습된 모델을 특정 작업에 맞게 추가 학습시키는 과정으로, 데이터셋과 목표에 따라 최적화됨.

- RLHF (Reinforcement Learning from Human Feedback) - 인간의 피드백을 기반으로 강화 학습을 수행하여 AI 모델을 더 정확하고 안전하게 만드는 기법.

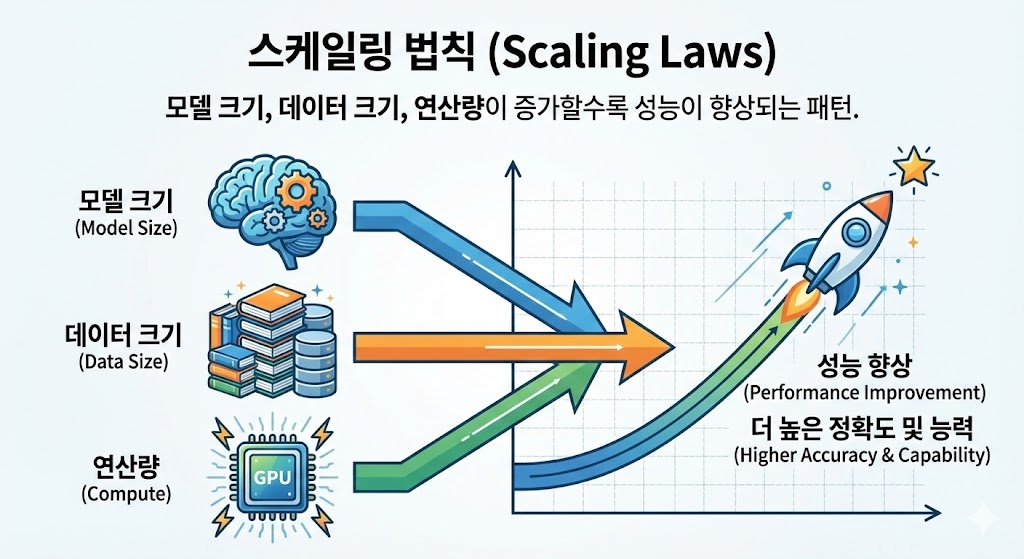
- 스케일링 법칙(Scaling Laws) - 모델 크기, 데이터 크기, 연산량이 증가할수록 성능이 향상되는 패턴을 설명하는 법칙.
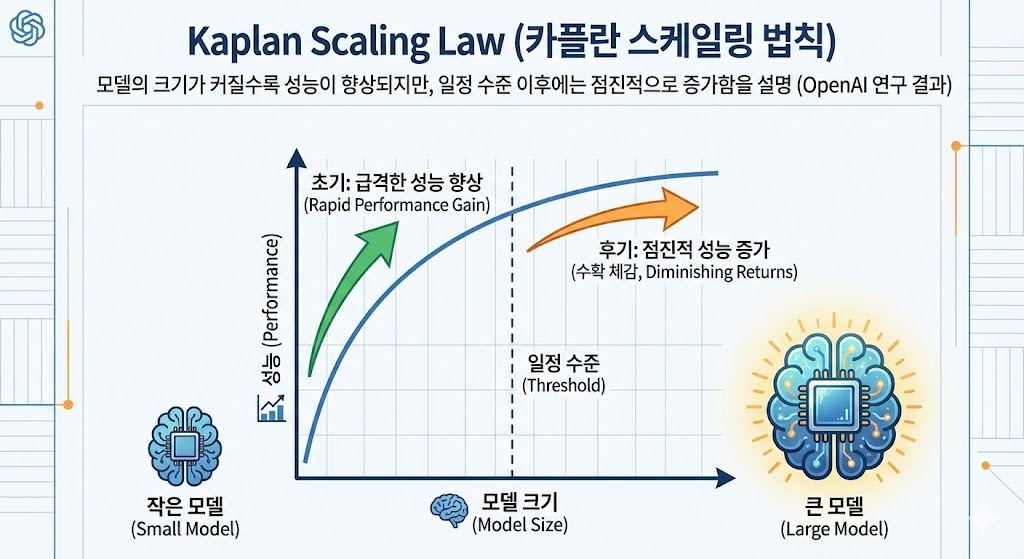
- Kaplan Scaling Law - 모델의 크기가 커질수록 성능이 향상되지만, 일정 수준 이후에는 점진적으로 증가함을 설명하는 OpenAI의 연구 결과.
- Chinchilla Scaling Law - 모델 크기뿐만 아니라 학습 데이터 크기도 중요한 요소이며, 균형 있는 확장이 필요함을 설명하는 DeepMind의 연구 결과.
- 멀티모달 AI(Multimodal AI) - 텍스트뿐만 아니라 이미지, 영상, 오디오 등 다양한 입력을 동시에 처리할 수 있는 인공지능 기술.
- MoE (Mixture of Experts) - 여러 개의 전문가 모델을 조합하여 작업을 수행하는 방식으로, 특정 작업에 적절한 서브 모델을 선택하여 연산을 최적화함.
- 지식 증강(External Knowledge Augmentation) - LLM이 외부 데이터베이스나 검색 시스템을 활용하여 최신 정보를 반영하는 방식.
- AI 정렬(Alignment) - AI 모델이 인간의 가치 및 윤리에 맞게 작동하도록 조정하는 과정.
- 편향(Bias) 문제 - LLM이 학습한 데이터에서 발생하는 편향된 정보가 결과물에 반영될 위험성.
- 컴퓨팅 비용(Computational Cost) - LLM을 훈련하고 운영하는 데 필요한 연산량과 하드웨어 리소스.
- 추론(Reasoning) - AI가 단순한 문장 생성뿐만 아니라 복잡한 논리적 판단을 수행하는 능력.
- 체인 오브 싱킹(Chain-of-Thought, CoT) - 단계별 추론 과정을 명시적으로 표현하여 LLM이 논리적으로 답을 도출하도록 유도하는 기법.
- 코드 생성(Code Generation) - LLM이 프로그래밍 코드 작성 및 디버깅을 지원하는 기능으로, OpenAI의 Codex 등이 대표적인 사례.
- OpenAI API - OpenAI에서 제공하는 AI 모델을 활용할 수 있는 인터페이스로, 개발자들이 다양한 응용 프로그램에 접목 가능.
- 데이터 증강(Data Augmentation) - 모델 학습을 위한 데이터 양을 증가시키기 위해 데이터를 변형하거나 생성하는 기법.
- 토큰(Token) - NLP 모델이 처리하는 기본 단위로, 단어, 문자 또는 서브워드 단위로 분할될 수 있음.
- Transformer Decoder - 트랜스포머 모델에서 다음 단어를 예측하는 데 특화된 구조로, GPT 계열 모델의 핵심 아키텍처.
- Self-Supervised Learning - 별도의 라벨 없이 데이터를 활용하여 모델이 스스로 학습하는 방식으로, LLM의 사전 학습 과정에 사용됨.
- Masked Language Model (MLM) - 문장에서 일부 단어를 가려놓고 모델이 이를 예측하도록 학습하는 방식으로, BERT 모델의 주요 학습 방법.
- Auto-Regressive Model - 한 번에 하나의 단어(토큰)씩 예측하며 텍스트를 생성하는 방식으로, GPT 계열 모델에서 사용됨.
- Zero-Shot Learning - 별도의 추가 학습 없이 LLM이 새로운 작업을 수행하는 능력.
- Few-Shot Learning - 소량의 예제(프롬프트)를 제공하면 모델이 해당 작업을 수행할 수 있도록 하는 학습 방식.
- Fine-Tuning with Task-Specific Data - 특정 작업에 맞게 LLM을 미세 조정하여 성능을 향상시키는 방법.
- Meta-Learning - 모델이 다양한 작업을 빠르게 학습할 수 있도록 돕는 기법으로, LLM의 적응 능력 향상에 기여함.
- Contrastive Learning - 모델이 서로 다른 문맥을 비교하며 더 나은 표현을 학습하도록 유도하는 학습 방식.
- Perplexity - 언어 모델의 성능을 평가하는 지표 중 하나로, 낮을수록 모델이 더 정확하게 예측함을 의미함.
- Gradient Descent Optimization - 신경망 모델이 손실을 최소화하기 위해 가중치를 조정하는 과정.
- Adam Optimizer - LLM 훈련 시 많이 사용되는 최적화 알고리즘으로, 학습 속도를 개선하고 안정성을 높임.
- Loss Function - 모델이 학습 중 오류를 최소화하도록 돕는 수학적 함수로, LLM에서는 Cross-Entropy Loss가 주로 사용됨.
- Backpropagation - 신경망 학습 과정에서 오류를 역전파하여 가중치를 조정하는 방법.
- Activation Function - 신경망에서 입력 신호를 변환하여 모델이 비선형적인 패턴을 학습할 수 있도록 하는 함수.
- Dropout Regularization - 모델이 과적합(overfitting)하는 것을 방지하기 위해 일부 뉴런을 무작위로 비활성화하는 기법.
- Data Preprocessing - 모델 학습 전에 데이터를 정제하고 변환하는 과정으로, 토큰화, 정규화, 중복 제거 등이 포함됨.
- Tokenization - 문장을 개별 단어 또는 서브워드 단위로 나누는 과정으로, BPE(Byte Pair Encoding)와 WordPiece가 대표적인 기법.
- Byte Pair Encoding (BPE) - 희귀 단어까지 효과적으로 표현할 수 있도록 하는 토큰화 기법으로, GPT 계열 모델에서 사용됨.
- Word Embeddings - 단어를 고차원 벡터로 변환하는 방식으로, 의미적 유사성을 반영할 수 있음.
- Vector Space Representation - 단어 또는 문장을 다차원 공간에 매핑하여 유사성을 계산하는 방식.
- Embedding Layer - LLM에서 단어를 벡터 형식으로 변환하는 계층.
- Positional Encoding - 트랜스포머 모델이 단어의 순서를 인식할 수 있도록 입력 데이터에 위치 정보를 추가하는 방식.
- Batch Normalization - 모델 학습 과정에서 각 레이어의 입력을 정규화하여 안정적인 학습을 유도하는 방법.
- Pretraining Corpus - LLM이 학습하는 데 사용되는 대규모 데이터셋으로, 웹 크롤링 데이터, 책, 논문 등이 포함될 수 있음.
- Transfer Learning - 한 작업에서 학습한 모델을 다른 작업에 재사용하는 학습 방식.
- Cross-Entropy Loss - 모델이 예측한 확률 분포와 실제 정답 간 차이를 계산하는 손실 함수.
- Gradient Clipping - 학습 중 급격한 그래디언트 변화로 인해 모델이 불안정해지는 현상을 방지하는 기법.
- Distributed Training - LLM의 훈련 속도를 높이기 위해 여러 GPU 또는 TPU를 활용하여 병렬 학습하는 방식.
- Federated Learning - 중앙 서버 없이 분산된 데이터에서 개별적으로 학습하고 모델을 통합하는 방식.
- Neural Network Pruning - 불필요한 가중치를 제거하여 모델 크기를 줄이고 속도를 향상시키는 방법.
- Attention Head - 트랜스포머 모델에서 특정 단어가 문맥 내에서 어떻게 관련되는지 평가하는 단위.
- Multi-Head Attention - 여러 개의 어텐션 헤드를 활용하여 다양한 관계를 학습할 수 있도록 하는 기법.
- Masked Self-Attention - GPT 모델처럼 문장의 앞부분만 참고하도록 제한하는 방식으로, 언어 생성 모델에서 사용됨.
- Retrieval-Augmented Generation (RAG) - LLM이 외부 데이터베이스에서 정보를 검색하여 보다 정확한 답변을 생성하는 방식.
- Parameter-Efficient Fine-Tuning (PEFT) - 기존 모델을 변경하지 않고 적은 양의 추가 학습으로 특정 작업에 적응하는 기법.
- MoE (Mixture of Experts) 모델 - 여러 개의 작은 모델을 조합하여 특정 작업에 적절한 전문가 모델을 선택해 학습하는 방식.
- Latent Variable Models - 데이터에서 숨겨진 구조를 찾아내는 확률적 모델로, LLM의 표현 학습에서 중요한 개념.
- Knowledge Distillation - 크고 복잡한 모델(교사 모델)의 지식을 작은 모델(학생 모델)로 압축하는 기술.
- Catastrophic Forgetting - LLM이 새로운 데이터를 학습하는 과정에서 이전 학습 내용을 잃어버리는 문제.
- Adversarial Training - 모델의 취약점을 보완하기 위해 고의적으로 어려운 입력을 학습에 포함시키는 방식.
- Open-Domain QA - 사전 정의된 문서가 아니라 웹 전체에서 정보를 찾아 답변하는 질의응답 시스템.
- Multi-Modal Fusion - 다양한 유형의 데이터를 결합하여 학습하는 방식으로, 텍스트+이미지, 텍스트+음성 등을 포함.
- Memory-Augmented Neural Networks (MANNs) - 신경망이 학습 과정에서 장기 기억을 유지할 수 있도록 하는 기술.
- Continual Learning - 새로운 정보를 학습하면서도 기존의 지식을 유지하는 AI 학습 방법.
- Hyperparameter Tuning - 모델 성능을 최적화하기 위해 학습률, 배치 크기, 드롭아웃 비율 등의 설정을 조정하는 과정.
- Gradient Accumulation - 메모리 제한이 있는 환경에서 배치 크기를 확장하기 위해 여러 스텝 동안 그래디언트를 누적하여 업데이트하는 기법.
- Sparse Attention - 계산량을 줄이기 위해 전체 문맥이 아닌 특정 부분에만 집중하도록 설계된 어텐션 메커니즘.
- Long-Context Learning - LLM이 긴 문서나 대화를 이해하고 적절하게 처리할 수 있도록 하는 기술.
- Positional Embeddings - 단어의 순서 정보를 보존하기 위해 트랜스포머 모델에서 사용되는 벡터 표현.
- Lexical Semantics - 단어의 의미 관계를 연구하는 분야로, LLM이 단어 간 유사성을 학습하는 데 중요한 개념.
- Syntactic Parsing - 문장의 문법 구조를 분석하여 각 단어 간 관계를 파악하는 과정.
- Morphological Analysis - 단어를 구성하는 형태소(의미를 가지는 최소 단위)를 분석하는 기술.
- Sentiment Analysis - 텍스트에서 감정을 분석하여 긍정적, 부정적, 중립적인 감정을 분류하는 작업.
- Named Entity Recognition (NER) - 문장에서 사람, 장소, 조직 등의 고유 명사를 식별하는 NLP 기술.
- Coreference Resolution - 문장에서 같은 대상을 지칭하는 표현(대명사 등)을 연결하여 해석하는 기법.
- Contextualized Word Representations - 단어가 사용된 문맥에 따라 의미가 달라지는 것을 반영하는 워드 임베딩 기법(BERT 등).
- Neural Machine Translation (NMT) - 신경망을 활용한 기계 번역 기술로, LLM을 기반으로 번역 성능을 크게 향상시킴.
- GANs (Generative Adversarial Networks) - 생성 모델과 판별 모델이 경쟁하며 데이터를 생성하는 방식으로, 텍스트 생성에도 응용됨.
- Variational Autoencoder (VAE) - 데이터를 저차원 공간에서 표현하고 샘플링할 수 있도록 하는 생성 모델 기법.
- Out-of-Distribution (OOD) Detection - 모델이 훈련되지 않은 새로운 데이터(배포 외 데이터)를 인식하고 대응하는 방법.
- Domain Adaptation - 특정 도메인에서 학습한 모델을 다른 도메인에서도 효과적으로 적용할 수 있도록 조정하는 기법.
- Knowledge Graphs - 개체 간의 관계를 구조화하여 모델이 논리적 추론을 할 수 있도록 지원하는 데이터 구조.
- Memory-Based Reasoning - 모델이 과거 정보를 기억하고 이를 바탕으로 추론하는 방식.
- Hierarchical Attention - 문장 내에서 중요한 정보를 계층적으로 처리하여 문맥을 더 깊이 이해하는 기법.
- Catastrophic Interference - 새로운 지식을 학습할 때 기존 학습된 지식이 손실되는 현상으로, LLM의 지속적인 학습 문제와 관련됨.
- Explainable AI (XAI) - AI 모델의 의사결정 과정을 해석하고 설명할 수 있도록 하는 기술.
- AutoML (Automated Machine Learning) - 머신러닝 모델의 최적화 및 튜닝을 자동화하여 개발을 용이하게 하는 기술.
- Differentiable Programming - 신경망 모델이 연속적으로 최적화될 수 있도록 미분 가능한 연산을 활용하는 방식.
- Quantum Machine Learning - 양자 컴퓨팅을 활용하여 AI 모델의 성능을 향상시키는 새로운 연구 분야.
반응형

